
Verified Expert in Engineering
巴拉特是一名数据科学家和开发人员,专门设计和开发交互式报告和工具,以促进决策. 他曾与小型初创公司和大型公司合作, such as Comcast, MetLife, 联合健康集团/ Optum, 杰弗逊健康中心. 巴拉特的一个项目带来了600万美元的收入, 另一个节省了1000万美元.
Expertise
Previous Role
Senior AnalystPREVIOUSLY AT

巴拉特是一名数据科学家和开发人员,专门设计和开发交互式报告和工具,以促进决策. 他曾与小型初创公司和大型公司合作, such as Comcast, MetLife, 联合健康集团/ Optum, 杰弗逊健康中心. 巴拉特的一个项目带来了600万美元的收入, 另一个节省了1000万美元.
PREVIOUSLY AT
社会网络分析正迅速成为满足各种专业需求的重要工具. 它可以为企业目标(如定向营销)提供信息,并识别安全或声誉风险. 社会网络分析还可以帮助企业实现内部目标:它提供了对员工行为和公司不同部门之间关系的洞察.
Organizations can employ a number of software solutions for 社会网络分析; each has its pros and cons, 适用于不同的用途. 本文的重点是微软的 Power BI是最常用的一种 数据可视化 tools today. 虽然Power BI提供了许多社交网络附加组件,但我们将在 R 创造更引人注目和灵活的结果.
本教程假设您理解 基本图论,特别是有向图. 另外,后面的步骤最适合Power BI Desktop,它只在Windows上可用. 读者可以在Mac OS或Linux上使用Power BI浏览器, 但是Power BI浏览器不支持某些功能, 例如导入Excel工作簿.
创建社交网络从收集连接(边缘)数据开始. 连接数据包含两个主要字段: source node and the target node-边缘两端的节点. 在这些节点之外, 我们可以收集数据来产生更全面的视觉洞察, 通常表示为节点或边缘属性:
1)节点属性
2)边缘属性
让我们看看一个社交网络的例子,看看这些属性是如何发挥作用的:

我们也可以使用悬停文本来补充或替换上述参数, 因为它可以支持其他不容易通过节点或边缘属性表示的信息.
定义了社交网络的不同数据特征, 让我们来看看Power BI中用于可视化网络的四种流行工具的优缺点.
| Extension | Arthur Graus的《欧博体育app下载》 | 网络导航器 | Advanced Networks by ZoomCharts(精简版) | 自定义可视化使用R |
|---|---|---|---|---|
| Dynamic node size | Yes | Yes | Yes | Yes |
| Dynamic edge size | No | Yes | No | Yes |
| 自定义节点颜色 | Yes | Yes | No | Yes |
| 复杂社会网络加工 | No | Yes | Yes | Yes |
| 节点配置文件图像 | Yes | No | No | Yes |
| Adjustable zoom | No | Yes | Yes | Yes |
| Top N连接过滤 | No | No | No | Yes |
| 自定义悬停信息 | No | No | No | Yes |
| 边缘颜色定制 | No | No | No | Yes |
| 其他高级功能 | No | No | No | Yes |
Arthur Graus的《欧博体育app下载》, 网络导航器, 和高级网络的ZoomCharts(轻版)都是合适的扩展来开发简单的社交网络,并开始与您的第一个社交网络分析.


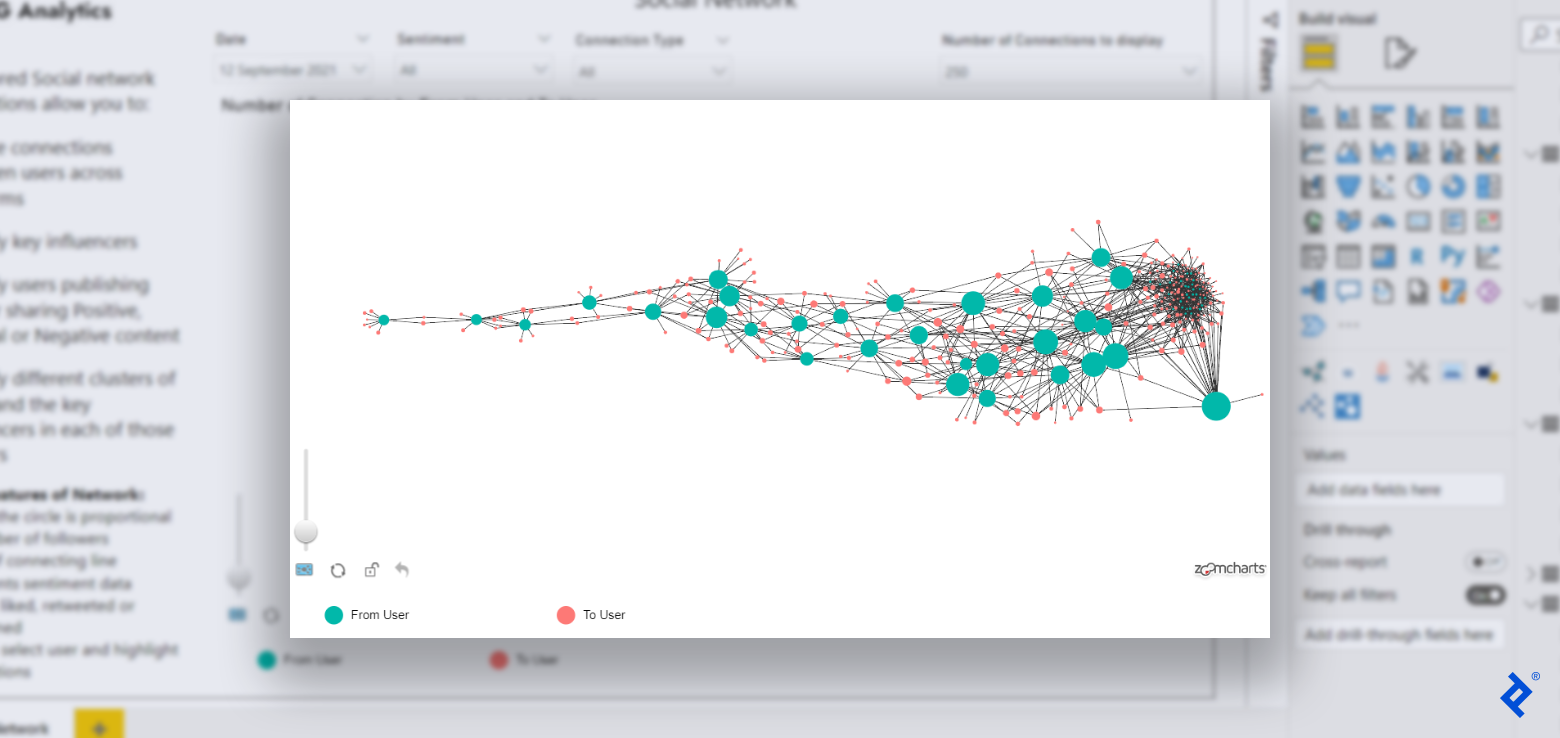
However, 如果你想让你的数据生动起来,并通过引人注目的视觉效果发现突破性的见解, 或者如果你的社交网络特别复杂, 我建议使用R开发自定义视觉效果.
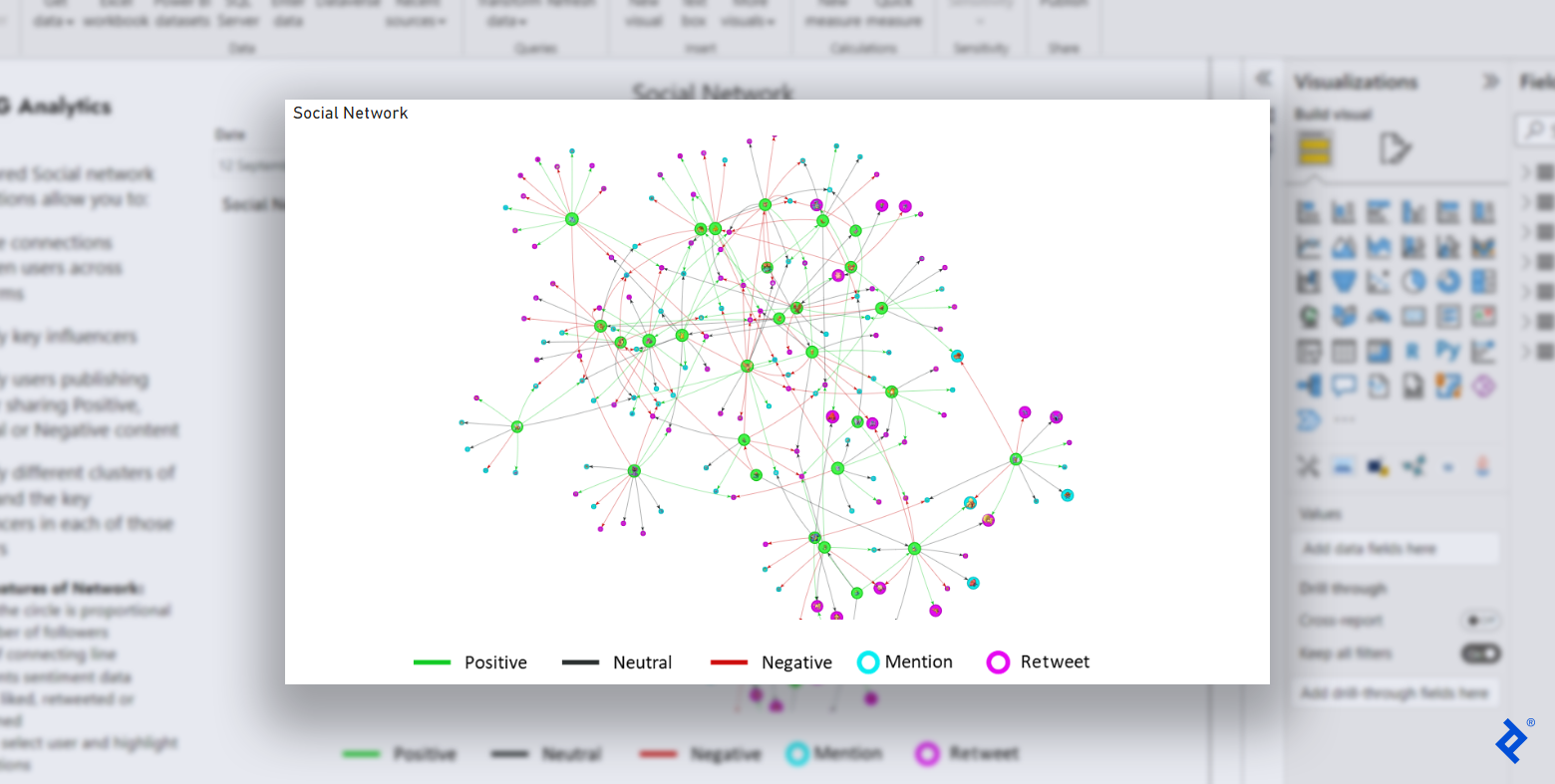
这个自定义可视化是本教程在R中的社交网络扩展的最终结果,它展示了R提供的大量特性和节点/边缘属性.
使用R在Power BI中创建可视化社交网络的扩展包括五个不同的步骤. 但是在我们建立我们的社交网络扩展之前,我们必须将我们的数据加载到Power BI中.
您可以使用 test dataset 基于Twitter和Facebook的数据,或者继续你自己的社交网络. Our data has been randomized; you may 下载真实Twitter数据 if desired. 收集所需数据后,将其添加到Power BI中(例如,通过 导入Excel工作簿 or adding data manually). 您的结果应该类似于下表:

设置好数据后,就可以创建自定义可视化了.
开发Power BI可视化并不简单——即使是基本的可视化也需要数千个文件. 幸运的是,微软提供了一个库 pbiviz,它仅用几行代码就提供了所需的基础设施支持文件. The pbiviz 库也将我们所有的最终文件重新打包到 .pbiviz 文件,我们可以将其直接加载到Power BI中作为可视化.
最简单的安装方法 pbiviz is with Node.js. Once pbiviz 安装后,我们需要通过机器的命令行界面初始化自定义R可视化:
pbiviz new toptalSocialNetworkByBharatGarg - rhtml
cd toptalSocialNetworkByBharatGarg
npm install
pbiviz package
别忘了更换 toptalSocialNetworkByBharatGarg 为您的可视化提供所需的名称. -t rhtml informs the pbiviz 包,它应该创建一个模板来开发基于r的HTML可视化. 您将看到错误,因为我们还没有在包中指定作者姓名和电子邮件等字段, 但我们将在本教程后面解决这些问题. If the pbiviz 脚本在PowerShell中根本无法运行,您首先可能需要允许使用 Set-ExecutionPolicy RemoteSigned.
成功执行代码后,您将看到一个具有以下结构的文件夹:

一旦我们准备好了文件夹结构,我们就可以为自定义可视化编写R代码了.
在第一步中创建的目录包含一个名为 script.r,它由默认代码组成. (默认代码创建一个简单的Power BI扩展,它使用 iris 样本数据库可用来绘制直方图 Petal.Length by Petal.Species.)我们将更新代码,但保留其默认结构,包括其注释部分.
我们的项目使用了三个R库:
中的代码替换 库声明 section of script.r 为了反映图书馆的使用情况:
libraryRequireInstall(图)
libraryRequireInstall(“visNetwork”)
libraryRequireInstall(“数据.table")
中的代码 Actual code 节中使用R代码. 在创建可视化之前,我们必须首先读取和处理我们的数据. 我们将从Power BI获取两个输入:
num_records:数字输入 N,这样我们将只选择最优秀的 N 来自我们网络的连接(限制显示的连接数)dataset:我们的社交网络节点和边缘To calculate the N 我们要绘制的连接,我们需要汇总 num_records 值,因为Power BI默认情况下会提供一个向量,而不是单个数值. 像这样的聚合函数 max 达到这个目标:
limit_connection <- max(num_records)
We will now read dataset as a data.table 具有自定义列的对象. 我们按值降序对数据集进行排序,将最频繁的连接放在表的顶部. 这可以确保我们在限制连接时选择最重要的记录进行绘图 num_records:
dataset <- data.Table (from = dataset[[1]])
,to = dataset[[2]]
,value = dataset[[3]]
,col_sentiment = dataset[[4]]
,col_type = dataset[[5]]
,from_name = dataset[[6]]
,to_name = dataset[[7]]
,from_avatar = dataset[[8]]
,to_avatar = dataset[[9]])[
order(-value)][
Seq (1, min(nrow(dataset), limit_connection))]
接下来,我们必须通过创建和分配唯一的用户id (uid),并将其存储在一个新表中. 我们还计算了用户总数,并将该信息存储在一个单独的变量中 num_nodes:
user_ids <- data.表id = unique(c(dataset$from))
数据集$to)))[, uid:= 1:.N]
num_nodes <- nrow(user_ids)
让我们用其他属性更新用户信息,包括:
We will use R’s merge function 更新表:
user_ids <- merge(user_ids, dataset[, .(num_follower = uniqueN(to)), from], by.x = 'id', by.y = 'from', all.x = T)[is.na(num_follower), Num_follower:= 0][, size := num_follower][num_follower > 0, [Size:= Size + 50], Size:= Size + 10]
user_ids <- merge(user_ids, dataset[, .(sum_val = sum(value)), .(to, col_type)][order(-sum_val)][, id:= 1].N, to][id == 1, .(to, col_type)], by.x = 'id', by.y = 'to', all.x = T)
User_ids [id %in% dataset$from, col_type:= '#42f548']
user_ids <- merge(user_ids, unique(rbind(dataset[, .('id' = from, 'Name' = from_name, 'avatar' = from_avatar)],
dataset[, .(“id”=“名字”= to_name,《欧博体育app下载》= to_avatar))))
by = 'id')
我们还添加了创建的 uid 到原始数据集,以便我们可以检索 from and to 后面代码中的用户id:
dataset <- merge(dataset, user_ids[, .(id, uid)],
by.x = "from", by.y = "id")
dataset <- merge(dataset, user_ids[, .(id, uid_retweet = uid)],
by.x = "to", by.y = "id")
user_ids <- user_ids[order(uid)]
接下来,我们为可视化创建节点和边缘数据帧. We choose the style and shape 的节点(填充圆圈),并选择我们的 user_ids 表来填充我们的节点 color, data, value, and image attributes:
nodes <- create_node_df(n = num_nodes,
type = "lower",
Style = "fill ",
Color = user_ids$col_type;
shape = 'circularImage',
数据= user_ids$uid,
Value = user_ids$size,
Image = user_ids$avatar,
title = paste0("Name: ", user_ids$Name,"
",
"Super UID ", user_ids$id, "
",
"# followers ", user_ids$num_follower, "
",
"
")
)
同样地,我们选择 dataset 与边对应的表列 from, to, and color attributes:
edges <- create_edge_df(from = dataset$uid,
To = dataset$uid_retweet;
arrows = "to",
Color = dataset$col_sentiment)
最后,准备好节点和边缘数据帧后,让我们使用 visNetwork 库并将其存储在默认代码稍后将使用的变量中,该变量名为 p:
p <- visNetwork(nodes, edges) %>%
visOptions(highlightNearest = list(enabled = TRUE, degree = 1, hover = T)) %>%
visPhysics(stabilization = list(enabled = FALSE), iterations = 10), adaptiveTimestep = TRUE, barnesHut = list(avoidOverlap = 0.2, damping = 0.15、重力常数= -5000))
在这里,我们自定义一些网络可视化配置 visOptions and visPhysics. 请随意浏览文档页面并根据需要更新这些选项. Our Actual code 节现在已经完成,我们应该更新 创建并保存小部件 通过移除线来分割 p = ggplotly(g); 因为我们编写了自己的可视化变量, p.
现在我们已经用R完成了编码, 我们必须对支持的JSON文件进行某些更改,以准备在Power BI中使用可视化.
让我们从 capabilities.json file. 它包含了您在 Visualizations 选项卡用于可视化,例如我们的扩展的数据源和其他设置. 首先,我们需要更新 dataRoles 并将现有值替换为我们的新数据角色 dataset and num_records inputs:
# ...
"dataRoles": [
{
“displayName”:“数据集”,
“description”:“连接详细信息-来自。, To, # of Connections, Sentiment Color, “到节点类型颜色”,
“类型”:“GroupingOrMeasure”,
"name": "dataset"
},
{
:“displayName num_records”,
“description”:“要保存的记录数量”;
“类型”:“测量”,
“名称”:“num_records”
}
],
# ...
In our capabilities.json 文件,我们也更新 dataViewMappings section. We’ll add conditions 我们的输入必须遵守,以及更新 scriptResult 以匹配我们的新数据角色及其条件. See the conditions 节,以及 select section under scriptResult, for changes:
# ...
“dataViewMappings”:(
{
"conditions": [
{
"dataset": {
"max": 20
},
"num_records": {
"max": 1
}
}
],
" scriptResult ": {
"dataInput": {
"table": {
"rows": {
"select": [
{
"for": {
"in": "dataset"
}
},
{
"for": {
“在”:“num_records”
}
}
],
" dataReductionAlgorithm ": {
"top": {}
}
}
}
},
# ...
让我们继续我们的 dependencies.json file. 在这里,我们将在 cranPackages 以便Power BI可以识别和安装所需的库:
{
"name": "data.table",
:“displayName的数据.table",
:“url http://cran.r-project.org/web/packages/data.table/index.html"
},
{
“名称”:“图”,
“displayName”:“图”,
:“url http://cran.r-project.org/web/packages/DiagrammeR/index.html"
},
{
“名称”:“visNetwork”,
:“displayName visNetwork”,
:“url http://cran.r-project.org/web/packages/visNetwork/index.html"
},
注意:Power BI应该自动安装这些库, 但是如果遇到库错误, 尝试运行以下命令:
install.软件包c(“DiagrammeR”,“htmlwidgets”,“visNetwork”,“data”).table", "xml2"))
最后,让我们为我们的视觉添加相关信息 pbiviz.json file. 我建议更新以下字段:
现在,我们的文件已经更新了,我们必须从命令行重新打包可视化:
pbiviz package
成功执行代码后,a .pbiviz 文件应创建在 dist directory. 本教程中涉及的全部代码可以在以下网站查看 GitHub.
在Power BI中导入新的可视化, 打开您的Power BI报告(现有数据或在我们的工作过程中创建的报告) Prerequisite 步骤(使用测试数据),并导航到 Visualizations tab. Click the … [更多选项]按钮并选择 从文件导入可视化. 注意:您可能需要先选择 Edit 在浏览器中按顺序进行 Visualizations TAB是可见的.

Navigate to the dist 目录,然后选择 .pbiviz 文件将您的视觉效果无缝加载到Power BI.
导入的可视化现在可以在可视化窗格中使用. 单击可视化图标以将其添加到报表中,然后将相关列添加到 dataset and num_records inputs:

您可以添加额外的文本, filters, 以及可视化的特性,这取决于项目需求. 我还建议您阅读我们用来进一步增强可视化的三个R库的详细文档, 因为我们的示例项目不能涵盖所有可用功能的用例.
我们的最终结果证明了R在创建自定义power BI可视化方面的强大功能和效率. Try out 社会网络分析 在你的下一个数据集上使用R中的自定义视觉效果, 并通过全面的数据洞察做出更明智的决策.
Toptal Engineering博客向 Leandro Roser 查看本文中提供的代码示例.

Power BI可帮助您创建具有交互式数据可视化的仪表板,可用于监控实时指标, analyze data, 做出商业决策.
Power BI并不难学, 特别是如果您有使用其他数据可视化工具的经验. UI是直观的,有大量的在线资源来帮助你开始. 然而,掌握所有Power BI特性和功能需要一个学习曲线.
社会网络分析可以用来理解群体中个体之间的关系. 这些信息可用于执行有针对性的营销和推广工作, 研究信息的传播, 了解社会网络的结构.
首先,选择一个社交网络进行分析. 然后,定义是什么构成了两个人之间的联系. 接下来,确定社交网络中的所有个体. 然后,确定个体之间的所有联系. 最后,分析连接以找到模式或趋势.
社会网络分析中的可视化是在数据中绘制关系和模式的过程,以便更好地理解社会系统的底层结构. 这可以通过多种方法来实现, 包括社交网络图, node-link图, and matrices.
是的,您可以使用R代码在Power BI中创建自定义视觉效果. 微软的pvibiz库通过仅用几行代码提供所需的基础设施来简化该过程.
Delhi, India
2020年6月24日成为会员
巴拉特是一名数据科学家和开发人员,专门设计和开发交互式报告和工具,以促进决策. 他曾与小型初创公司和大型公司合作, such as Comcast, MetLife, 联合健康集团/ Optum, 杰弗逊健康中心. 巴拉特的一个项目带来了600万美元的收入, 另一个节省了1000万美元.
PREVIOUSLY AT
世界级的文章,每周发一次.
世界级的文章,每周发一次.
Join the Toptal® community.