
验证专家 在工程
Juan是一名开发人员, 数据科学家, 他是布宜诺斯艾利斯大学研究社交网络的博士研究员, AI, and NLP. Juan拥有十多年的数据科学经验,并在ML会议上发表过论文, 包括SPIRE和ICCS.
以前在

Juan是一名开发人员, 数据科学家, 他是布宜诺斯艾利斯大学研究社交网络的博士研究员, AI, and NLP. Juan拥有十多年的数据科学经验,并在ML会议上发表过论文, 包括SPIRE和ICCS.
以前在
本文是关于使用R和Gephi进行Twitter聚类分析的三部分系列文章中的第一部分. 第二部分将 深化分析 we start today to better identify principal actors and understand topic spread; part three uses 聚类分析 从关于美国政治的两极分化的帖子中得出结论.
社交网络分析诞生于1934年,由雅各布·列维·莫雷诺创立 社会关系网图社会互动的抽象. 具体地说, 社交图是一个图,其中每个节点代表一个人,边代表他们之间的相互作用. 莫雷诺用社会关系图来研究一小群人的行为.
Why small? 因为在他工作的那个年代, 很难获得大量个人互动的详细信息. 随着Twitter等在线社交网络的出现,这种情况发生了变化. Nowadays, 任何人都可以免费下载大量Twitter数据, 这为有趣的分析打开了大门, 促使我们对自己的行为方式以及各种行为对社会的影响有了新的认识.
在我们的社交网络分析系列的第一部分, 方法来执行其中的一些分析 R语言 获取和预处理数据,以及 Gephi 产生惊人的视觉效果. Gephi是一个开源应用程序,专门设计用于可视化任何类型的网络. 它使用户能够通过几个标准和属性轻松地配置可视化.
如果你没有推特 developer 创建帐号,并申请 必要的访问. 然后,要下载Twitter数据,在 Twitter开发者门户. 接下来,在Projects中选择您的应用程序 & 应用程序部分,然后进入Keys & 令牌选项卡. 在那里,您必须生成您的凭据. 这些将用于访问 Twitter API 下载数据.
生成凭据之后,就可以开始分析了. 我们将使用三个R库:
控件安装这些库 install.包() function. 为了我们的目的, 我们假设你已经安装了R和RStudio, 你对它们有一个基本的了解.
在我们的演示中,我们将分析关于著名阿根廷足球运动员的激烈在线讨论 梅西 这是他在巴黎圣日耳曼(PSG)足球俱乐部的第一周. 需要注意的是,使用免费的Twitter API,您只能在当前日期之前7天内下载tweet. 你将无法下载我们引用的相同数据, 但是你可以下载当前的讨论.
让我们从下载开始. First, 我们将加载库, 然后使用凭证创建一个授权令牌, 最后设置 下载标准.
这个代码块详细说明了如何实现这三个步骤:
##加载库
库(rtweet)
库(igraph)
库(tidyverse)
##创建Twitter令牌
token <- create_token(
app = ,
consumer_key = ,
consumer_secret = ,
access_token =,
access_secret = )
##下载推文
tweets.df <- search_tweets("messi", n=250000,token=token,retryonratelimit = TRUE,until="2021-08-13")
##保存R上下文图像
save.图像(“文件名.RData")
Note: Replace all the tags between <> with the information that you created in the previous credentials step.
用下面的代码, 我们查询了所有tweet(最多250条)的Twitter API,其中包含“梅西”一词,于8月8日发布, 2021, 及八月十三日, 2021. 我们设定的上限是250,因为Twitter需要一个数量值,而且这个数字足够大,可以进行有趣的分析.
Twitter的下载率是45%,每15分钟000条推文, 下载250个,000条推文花了一个多小时.
Finally, 我们将所有上下文变量保存在RData文件中,以便在关闭RStudio或关闭机器时能够恢复它.
一旦下载完成,我们将在 tweets.df dataframe. 这个数据框矩阵包含每个tweet的一行和每个tweet字段的一列. First, 我们将使用它来创建交互图,其中每个节点代表一个用户, 边表示它们之间的交互(转发或提及). 使用tidyverse和igraph,我们可以在一个语句中快速创建这个图:
##创建图形
过滤器(微博.df, retweet_count > 0) %>%
select(screen_name, mentions_screen_name) %>%
unnest(mentions_screen_name) %>%
filter(!is.na(mentions_screen_name)) %>%
graph_from_data_frame() -> net
执行这一行之后,我们在 net 准备好进行分析的变量. 例如,要查看存在多少个节点和边:
# IGRAPH fd955b4 DN—138963 217362—
我们的样本数据产生138,000个节点和217,000条边. 这是一个很大的图表. 如果我们想,我们可以通过R生成可视化, 但根据我的经验, 它们需要很长时间来计算,并且不像Gephi可视化那样具有视觉吸引力. 因此,让我们从基腓书开始.
首先,我们需要创建一个Gephi可以读取的文件. 这很简单,因为我们可以生成a .gml 文件使用 write_graph function:
messi_network write_graph(简化(净)。.Gml ", format = " Gml ")
打开Gephi,打开图形文件,搜索 messi_network.gml 文件,并打开它. 它将弹出一个窗口,总结图形信息. 选择接受. 这将出现:

不用说,这不是很有用. 这是因为我们还没有应用布局.
在具有数千个节点和边的图中,在图中定位节点是至关重要的. 这就是布局的目的. 它们将节点放置在根据定义的标准设置的位置上.
对于我们的社交网络分析教程,我们将使用 ForceAtlas2布局,这是这类分析的标准选项. 它通过模拟节点之间的物理吸引力和排斥力来定位节点. 双节点连接, they will be in closer proximity to each other; if they aren’t connected, 他们会离得更远. 这种布局产生了一个关于社区的信息图表, 因为属于同一社区的用户将被分组在一起,而来自不同社区的用户将位于不同的区域.
将这个布局应用到我们的案例中, 我们导航到布局窗口(在左下角), 选择ForceAltas 2, 并单击Run. 当您这样做时,您将看到节点开始移动并形成许多“云”.“几秒钟后,你会有一个非常稳定的模式,你可以点击停止. 请注意,自动停止可能需要很长时间.
由于这是一个随机算法,每次运行的输出将略有不同. 你的输出应该类似于这样:

这张图表开始显得很有吸引力. 现在我们给它加点颜色.
We can color nodes using several criteria; the most standard approach is 由社区. 如果图中有四个群落,就有四种颜色. 根据您的数据,通过颜色,更容易理解组之间的相互作用.
为了给节点上色,首先我们必须确定社区. In Gephi, 单击窗口中Statistics选项卡下的Modularity按钮—此按钮应用流行的模块 Louvain 图聚类算法, 最快的可用算法之一, 由于其高性能而被认为是最先进的. 在出现的窗口中,单击Accept. 将出现另一个窗口,其中包含 散点图 按大小分布的社区. 现在我们在每个节点中都有一个名为Modularity Class的新属性, 哪个包含用户拥有的社区.
完成了前面的步骤后,我们现在可以通过聚类给图上色了. 为此,在Appearance选项卡中,单击Apply.
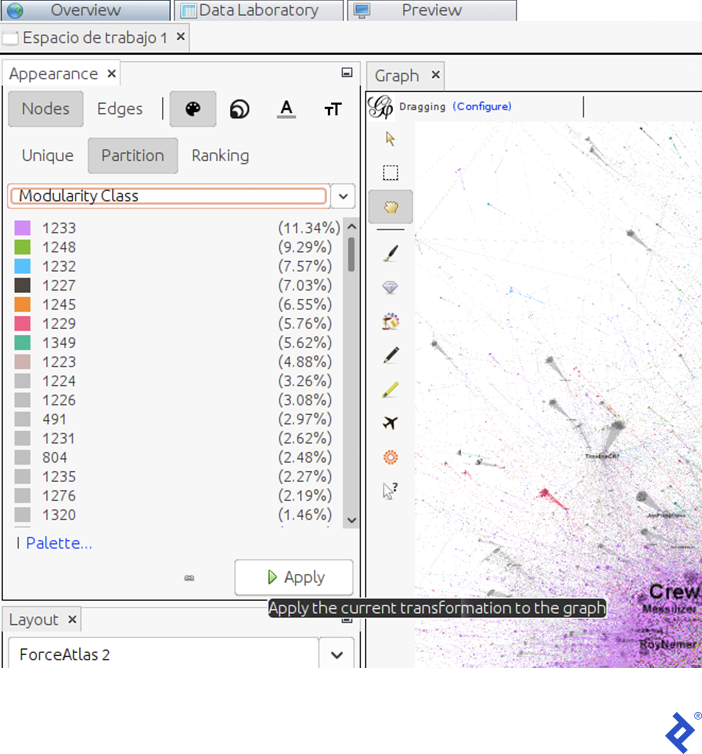
这里我们可以看到每个社区的规模(以用户百分比计算). 在我们的例子中,主要社区(紫色和绿色)包含11个.34% and 9.分别占总人口的29%.
使用当前的布局和调色板,图形看起来像这样:

Finally, 我们想确定讨论的主要参与者,以便了解, 例如, 谁属于哪个社区. We can measure the influence of each user by different properties; one of them is by their degree. 这表明有多少用户转发或提到了它们.
通过大量的交互来突出用户, 我们将使用Degree属性改变节点的大小:
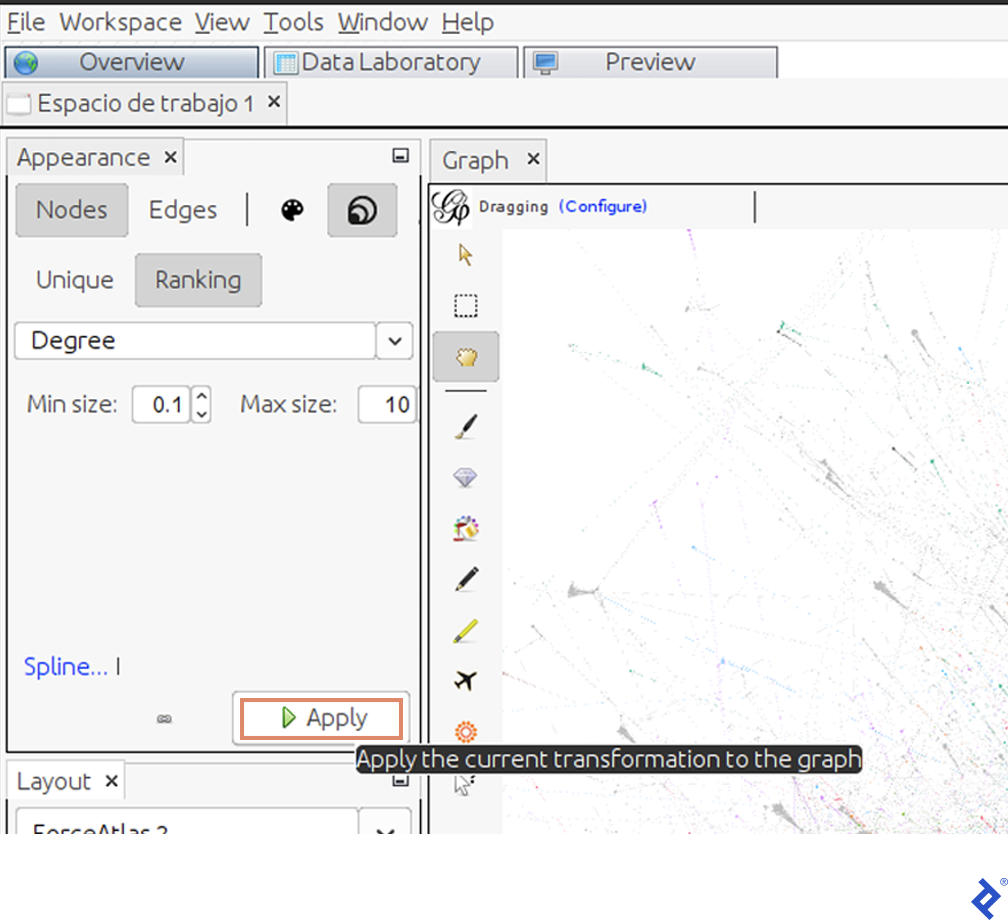
图表现在将显示影响者为节点,用更大的圆圈表示:

现在我们已经确定了有大量交互的用户,我们可以透露他们的名字. 要做到这一点,请单击屏幕底部栏中的黑色箭头:

然后单击“标签和配置”. 在出现的窗口中,选择Name复选框并单击Accept. 接下来,单击Nodes复选框. 图中会出现小黑线. 这些是所有用户的名字. 但我们不想看到 所有的,只是最重要的.
要定义它们,请使用我们用于节点大小的相同窗口,按节点度更改它们的大小. 我们从0增加了最小大小.从1到10,并将最大大小从10增加到300.
加上名字, 图表的信息量显著增加, 因为它展示了不同社区如何与影响者互动:
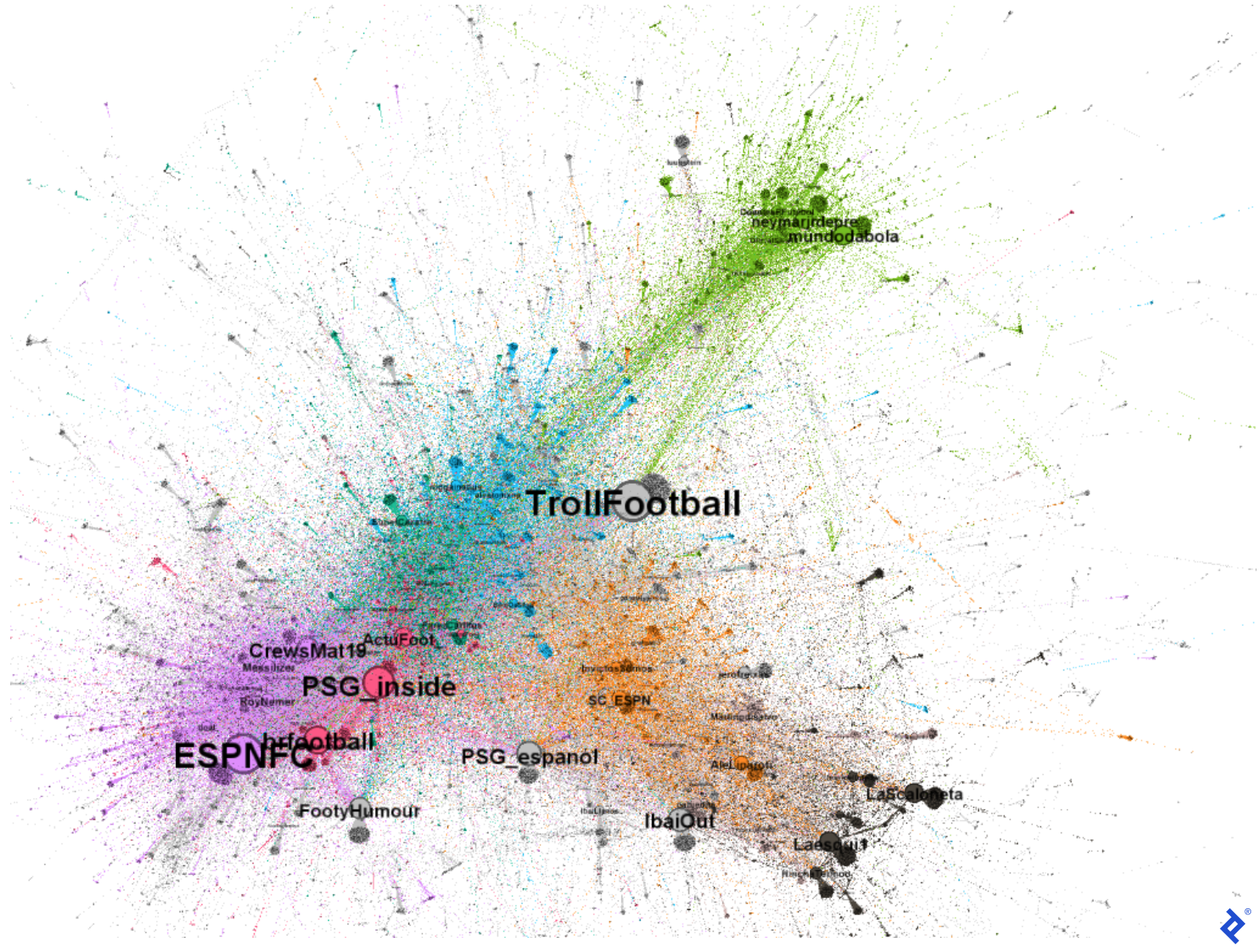
我们现在对这个特定的Twitter讨论有了更多的了解. 例如,绿色社区的账户包括 mundodabola and neymarjrdepre 揭示它的巴西轨迹. 橙色和灰色的社区包含西班牙语用户,比如 sc_espn and InvictosSomos. 特别是,灰色和黑色社区似乎是讲西班牙语的,因为他们有用户喜欢 IbaiOut, LaScaloneta和流行的主播 IbaiLlanos. Finally, 紫色和红色社区似乎是说英语的,因为他们的账户是这样的 ESPNFC and brfootball.
现在我们可以更好地理解为什么这些用户组成了不同的社会学社区,而不仅仅是图计算:他们说不同的语言! 他们都在推特上谈论梅西和他的新球队,但说西班牙语的人与其他说西班牙语的人的互动多于说葡萄牙语或英语的人,这是有道理的. Moreover, 我们也可以理解,即使灰色和橙色社区说西班牙语, 他们从不同的角度来做这件事. 灰色社区用一种更幽默的方式解释了为什么他们彼此之间的互动比官方足球或记者账户更多.
如果我们不使用Gephi来绘图,我们可以使用R的Ggplot库. 然而,从我的角度来看,这个库在网络绘图方面受到了更多的限制. 它不像Gephi一样是动态的, 它更难以配置, 结果显示不太清晰.
在本系列的其余部分中,我们将进一步对此进行分析. 我们执行一些主题建模 text analyses to see how much users are talking and what topics are of interest to them; we will conduct a sentiment analysis to see if they are being positive or negative; and we will do a deeper graph analysis to analyze Twitter’s biggest influencers.
您可以使用这些步骤来分析新的Twitter讨论,并查看可以从图表中获得哪些见解.
R最初是为统计分析和学术研究人员设计的. However, 如今,它被广泛用于许多其他目的, 例如机器学习开发或动态报表设计.
这取决于. 它们都是伟大的语言,有大量的社区支持它们. 一些功能在R中有更好的库,而在Python中有更好的库.
Yes, R是一种高级语言,最初是为没有丰富编程知识的用户设计的, 比如数学家和物理学家. 这就是为什么它是一种非常用户友好和易学习的语言.
社会网络分析用于了解人们如何互动以及他们互动的性质. 它可以用来寻找新的客户、市场、合作伙伴,甚至投资者.
First, 您从在线社交网络获取数据, 然后构建交互图并开始分析网络行为.
可能两者都有,取决于你的背景. 工程师可以进行定量分析,而社会学家可以进行定性分析.
社会图是一种图形,其中每个节点都是一个人,边缘表示他们之间的互动.
社会关系图很重要,因为它们为我们提供了人们在庞大群体中如何互动的抽象(和说明). 它们很简单,但很有意义. 它们帮助我们从多个角度理解社会, 比如用户中心性, 信息传播, 社区识别, and more.
世界级的文章,每周发一次.
世界级的文章,每周发一次.